The blockchain is a file of transactions. It’s the most significant file that a bitcoin node maintains.
It is called the “blockchain”, because new transactions are added to the file in blocks, built on top of the previous block to create a chain of blocks.
But ultimately, the blockchain is permanent storage for bitcoin transactions.
Each block within the blockchain is identified by a hash. This hash is generated using the SHA256 cryptographic hash algorithm on the header of the block. The block also references a previous block, known as the parent block.
When a node successfully mines a new block, they will share it with the other nodes on the network. When other nodes receive this new block, they will add it to their blockchain.
What happens if two blocks are mined at the same time?
Sometimes, two nodes find different blocks at the same time.
In this situation, nodes will consider the first block they receive as part of their blockchain, but also keep the second block they receive just in case. However, the second block to arrive (and the transactions inside it) will not be considered as part of their active blockchain.
Ultimately, some nodes will disagree about the active chain. This disagreement is resolved when the next block is mined. The next block will build on top of one of these blocks, creating a new longest chain of blocks. As a rule, nodes will always adopt the longest known chain of blocks as their active blockchain.
The 51% Attack
Due to the fact that nodes always adopt the longest chain, you could always try and build a new longer chain of blocks to replace an existing one. Every node on the network will adopt it. This would allow you to reverse transactions from the blockchain.
However, the problem is that all miners are incentivised to always be building on to the longest known chain. This means that the combined processing power of miners on the network will be focused on building one single chain, which will be built faster than any chain you could build on your own.
But in case you control more than 50 percent of the mining power, you could find blocks faster and possibly build a longer chain. This is known as the 51% Attack.
Like we learned earlier, a child block includes a hash of the previous block hash. If the parent is modified in any way, the parent’s hash changes. Therefore, in order to change a lower block, you need to change the children and eventually the grandchildren. This cascade effect ensures that once a block has many generations following it, it cannot be changed without forcing a recalculation of all subsequent blocks. In that way, a block becomes more secure if new blocks are find.
Despite its name, the 51% attack scenario doesn’t actually require 51% of the hashing power. In fact, the 51% threshold is simply the level at which such an attack is almost guaranteed to succeed.
Structure of a Block
The block is made of a header, containing metadata, followed by a long list of transactions that make up the bulk of its size.
| Size | Field | Description |
|---|---|---|
| 4 bytes | Block Size | The size of the block, in bytes, following this field |
| 80 bytes | Block Header | Several fields form the block header |
| 1–9 bytes (VarInt) | Transaction Counter | How many transactions follow |
| Variable | Transactions | The transactions recorded in this block |
Block Header
The block header is the summary of the data in the block. It consists of three sets of block metadata:
- reference to the previous block
- reference to the mining competition (difficulty, timestamp, and nonce)
- Merkle tree root
For example, here is the block header for block 123456:
010000009500c43a25c624520b5100adf82cb9f9da72fd2447a496bc600b0000000000006cd862370395dedf1da2841ccda0fc489e3039de5f1ccddef0e834991a65600ea6c8cb4db3936a1ae3143991
It’s structured like this:
Version | Previous Block | Merkle Root | Timestamp | Difficulty | Nonce
| Size (bytes) | Field | Description |
|---|---|---|
| 4 | Version | A version number to track software/protocol upgrades |
| 32 | Previous Block Hash | A reference to the hash of the previous (parent) block in the chain |
| 32 | Merkle Root | A hash of the root of the merkle tree of this block’s transactions |
| 4 | Timestamp | The approximate creation time of this block (in seconds elapsed since Unix Epoch) |
| 4 | Difficulty Target | The Proof-of-Work algorithm difficulty target for this block |
| 4 | Nonce | A counter used for the Proof-of-Work algorithm |
The nonce, difficulty target, and timestamp will be discussed in the next chapter.
Block Identifiers
There are two ways to identify a block:
- block header hash
- block height
The primary identifier of a block is its cryptographic hash. This block hash might be stored in a separate database table as part of the block’s metadata, to facilitate indexing and faster retrieval of blocks from disk.
In addition, the term current block height indicates the size of the blockchain in blocks at any given time.
Sidenote: A block’s block hash always identifies a single block uniquely. A block also always has a specific block height. However, it is not always the case that a specific block height can identify a single block. Rather, two or more blocks might compete for a single position in the blockchain.
Bitcoin full nodes maintain a local copy of the blockchain, starting at the genesis block. As a node receives incoming blocks from the network, it will validate these blocks and then link them to the existing blockchain. To establish a link, a node will examine the incoming block header and look for the “previous block hash”.
Merkle Trees
Each block in the bitcoin blockchain contains a summary of all the transactions in the block, using a merkle tree.
A merkle tree, also known as a binary hash tree, is a data structure used for efficiently summarizing and verifying the integrity of large sets of data. Merkle trees are binary trees containing cryptographic hashes.
A merkle tree is constructed by recursively hashing pairs of nodes until there is only one hash, called the root, or merkle root. The cryptographic hash algorithm used in bitcoin’s merkle trees is SHA256 applied twice, also known as double-SHA256.
When N data elements are hashed and summarized in a merkle tree, you can check to see if any one data element is included in the tree with at most 2*log2(N) calculations.
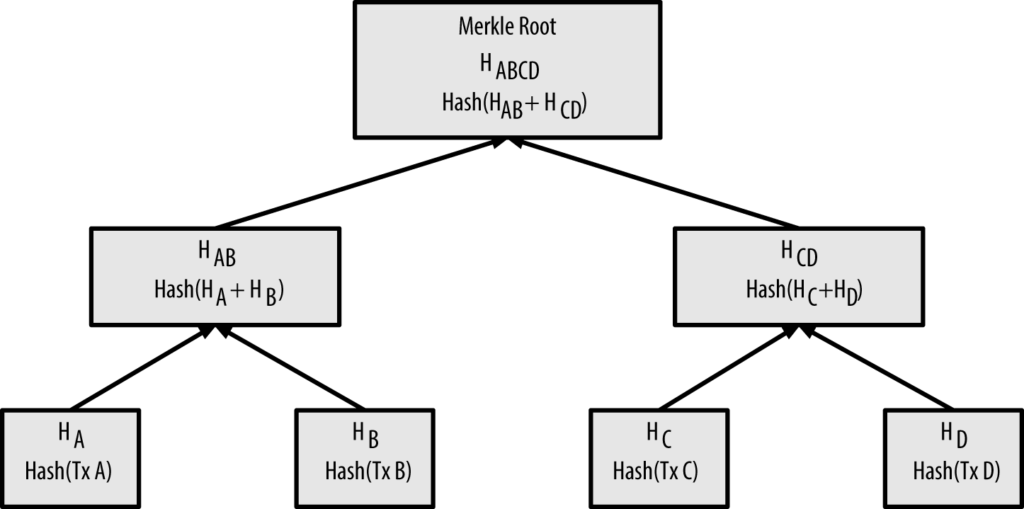
Because the merkle tree is a binary tree, it needs an even number of leaf nodes. If there is an odd number of transactions to summarize, the last transaction hash will be duplicated to create an even number of leaf nodes (balanced tree).
Merkle Trees an SPV nodes
Nodes that do not maintain a full blockchain use merkle paths to verify transactions without downloading full blocks.
Let’s look at a merkle tree with 16 transactions:
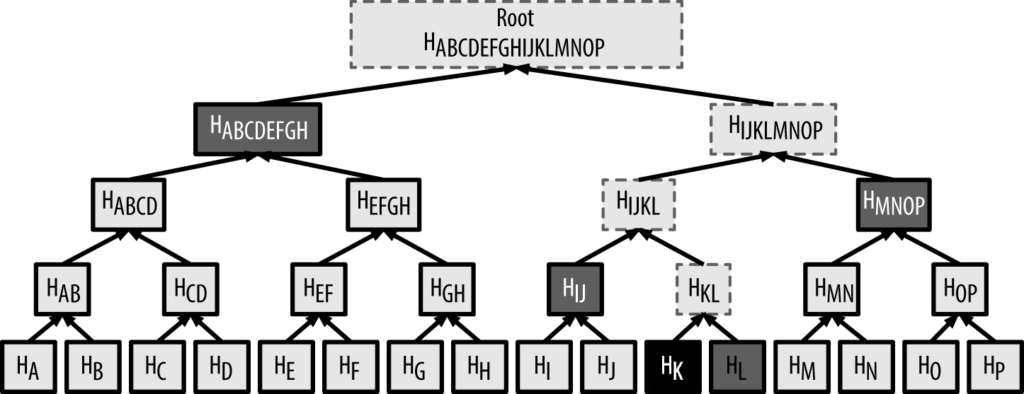
You want to know if the transaction HK is in the block. Therefore, you only need 4 other hashes (HL, HIJ, HMNOP, and HABCDEFGH) to calculate the merkle root. If it matches with the merkle root in the block header, the transaction is in the block.
The SPV node will establish a bloom filter on its connections to peers to limit the transactions received to only those containing addresses of interest. When a peer sees a transaction that matches the bloom filter, it will send that block using a merkleblock message. This message contains the block header as well as a merkle path that links the transaction of interest to the merkle root in the block.
The SPV node can now connect the transaction to the block and verify that the transaction is included in the block. In addition, the SPV node also uses the block header to link the block to the rest of the blockchain.
The efficiency of merkle trees becomes obvious as the scale increases:
| Number of transactions | Approx. size of block | Path size (hashes) | Path size (bytes) |
|---|---|---|---|
| 16 transactions | 4 kilobytes | 4 hashes | 128 bytes |
| 512 transactions | 128 kilobytes | 9 hashes | 288 bytes |
| 2048 transactions | 512 kilobytes | 11 hashes | 352 bytes |
| 65,535 transactions | 16 megabytes | 16 hashes | 512 bytes |
Sidenote: SPV nodes can verify that a transaction is in a block. However, they can’t tell if a transaction is not in a block.
Bitcoin’s Test Blockchains
Actually, there is more than one bitcoin blockchain. The “main” bitcoin blockchain is called mainnet. There are other bitcoin blockchains that are used for testing purposes: at this time testnet, segnet, and regtest.
Testnet
The test blockchain, network and currency for testing purposes is called testnet. It has all the functionalities like the mainnet, there are only 2 differences:
- coins are worthless
- low mining difficulty
In order to maintain these differences, the testnet has to be scrapped and restarted from a new genesis block, resetting the difficulty. Currently we are in the third iteration of testnet (testnet3).
Segnet
In 2016, a special-purpose testnet was launched to aid in development and testing of Segregated Witness. This test blockchain is called segnet and can be joined by running a special version (branch) of Bitcoin Core.
Since segwit was added to testnet3, it is no longer necessary to use segnet for testing of segwit features.
In the future, it’s likely we will see other testnet blockchains that are specifically designed to test a single feature or major architectural change.
Regtest
Regtest (Regression Testing) is a Bitcoin Core feature that allows you to create a local blockchain for testing purposes. Unlike testnet3, which is a public and shared test blockchain, the regtest blockchains are intended to be run as closed systems for local testing. You launch a regtest blockchain from scratch, creating a local genesis block. Additionally, you may add other nodes to the network, or run it with a single node only to test the Bitcoin Core software.
In conclusion, you should use the test blockchains whether you are developing. As you make changes, improvements, bug fixes, etc., start the pipeline again, deploying each change first on regtest, then on testnet, and finally into production.